Wstęp do algorytmów grafowych
Grafy
Popularna anegdota głosi, że od każdego człowieka na Ziemi dzieli nas co najwyżej sześć stopni znajomości: można wysłać do każdego wiadomość, podając ją sobie z rąk do rąk wyłącznie między znajomymi. Bardzo ciężko zweryfikować, jak jest w rzeczywistości, jednak upowszechnienie się portali społecznościowych dostarcza ciekawego materiału do analizy – a nam dobrej ilustracji pojęcia grafu, a także składowych, ścieżek i odległości w grafach.
Wyobraźmy sobie portal społecznościowy i pewną liczbę jego użytkowników. Niektórzy z nich są wirtualnymi "znajomymi", inni zaś nie są. Naturalnym sposobem przedstawienia takiej sytuacji jest rysunek złożony z punktów i łączących je linii:
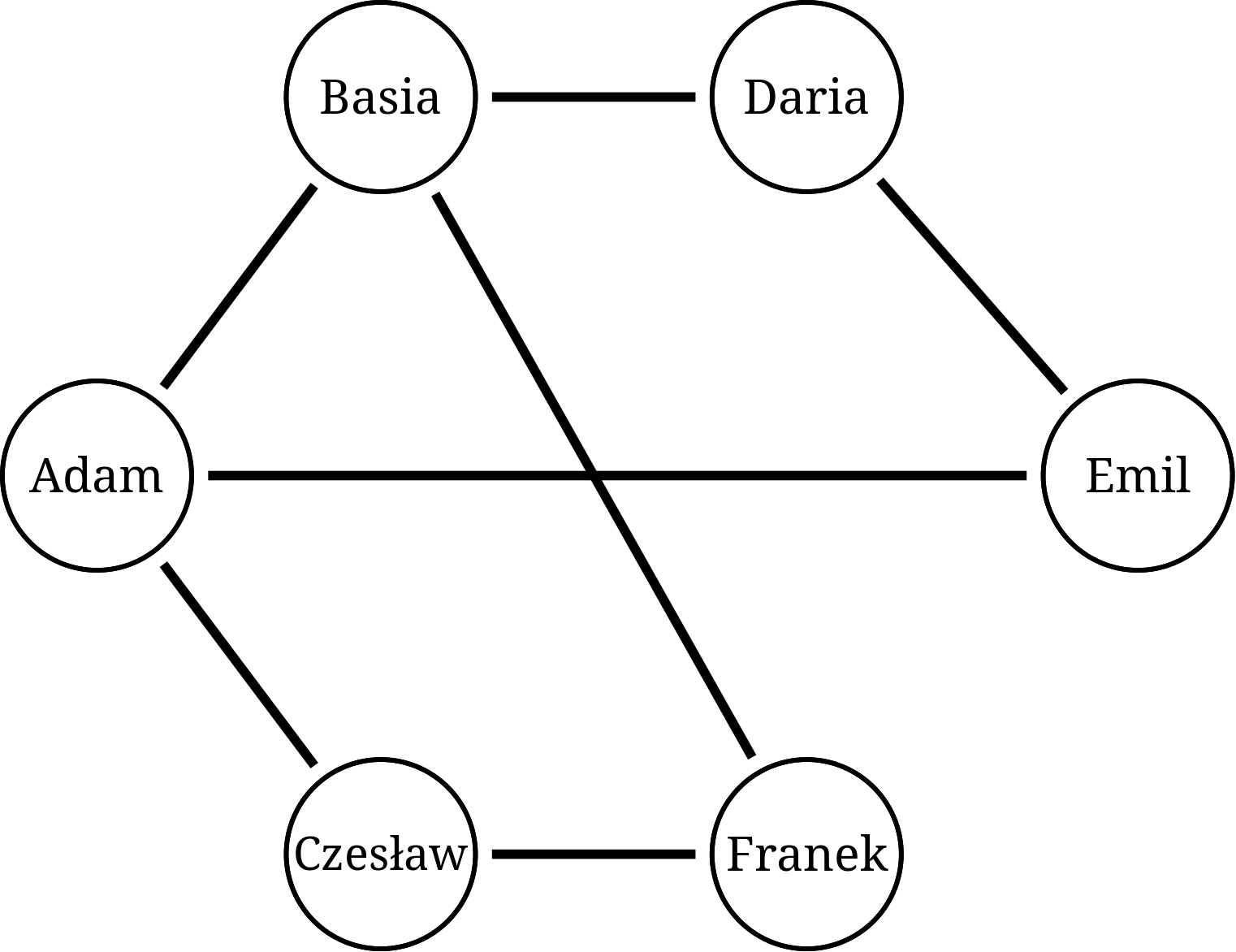
Na tym rysunku Adam zna Basię i Czesława, Basia zna Adama, Darię i Franka, Czesław zna Adama i Franka, itd. Schemat takiej sieci połączeń w języku informatyki nazywamy grafem. Formalnie: graf to pewien zbiór wierzchołków (wierzchołkami w naszym wypadku są osoby w sieci społecznościowej) oraz łączących je krawędzi - każda krawędź to po prostu para wierzchołków. W naszym wypadku krawędziami są znajomości między osobami (znajomość Adam-Czesław to krawędź między wierzchołkami A i C).
Pojęcie grafu ma niesamowitą wręcz ogólność i szerokość zastosowań. Jako graf możemy przedstawić mapę połączeń londyńskiego metra:
 Żródło: http://en.wikipedia.org
Żródło: http://en.wikipedia.org
...gdzie wierzchołkami są stacje, a krawędziami – odcinki linii. Grafem może być też schemat zależności między językami Europy:

Żródło: Teresa Elms, http://elms.wordpress.com
Wierzchołkami są tu języki, a krawędzie rysujemy wtedy, kiedy języki są do siebie podobne.
Dygresja techniczna I: Graf w pamięci komputera
Są dwa powszechnie stosowane sposoby przechowywania grafu w pamięci. Pierwszy nazywa się macierzą sąsiedztwa (albo tablicą sąsiedztwa) i jest to dwuwymiarowa tablica, w której każdej parze wierzchołków przypisujemy wartość 1, jeśli jest między nimi krawędź, 0 jeśli jej nie ma.
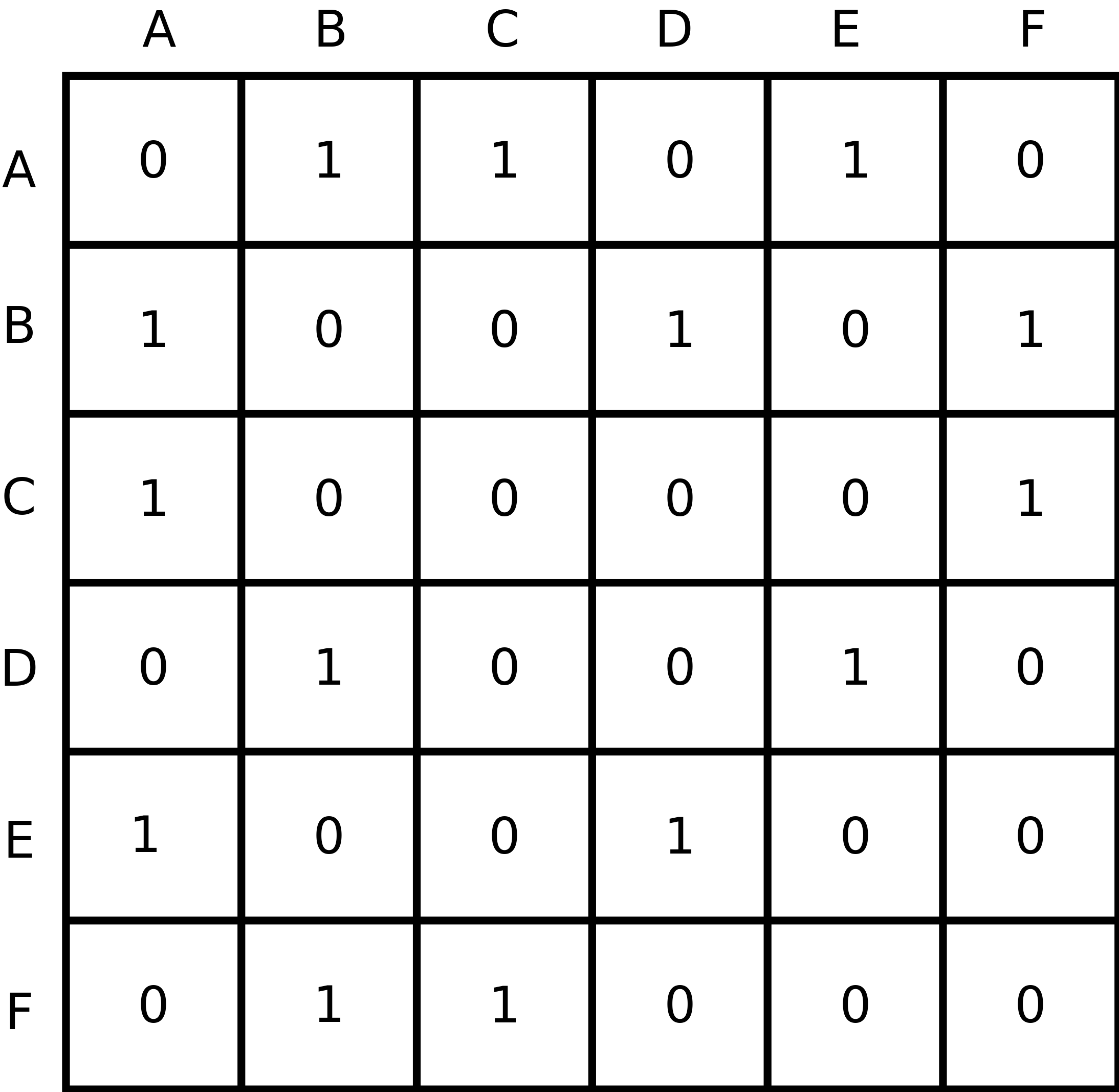
Na przykład krawędź A - E reprezentowana jest przez jedynkę w pierwszym wierszu i piątej kolumnie (a także w piątym wierszu i pierwszej kolumnie).
Drugi sposób to trzymać dla każdego wierzchołka listę jego sąsiadów, czyli wierzchołków, z którymi połączony jest krawędzią:
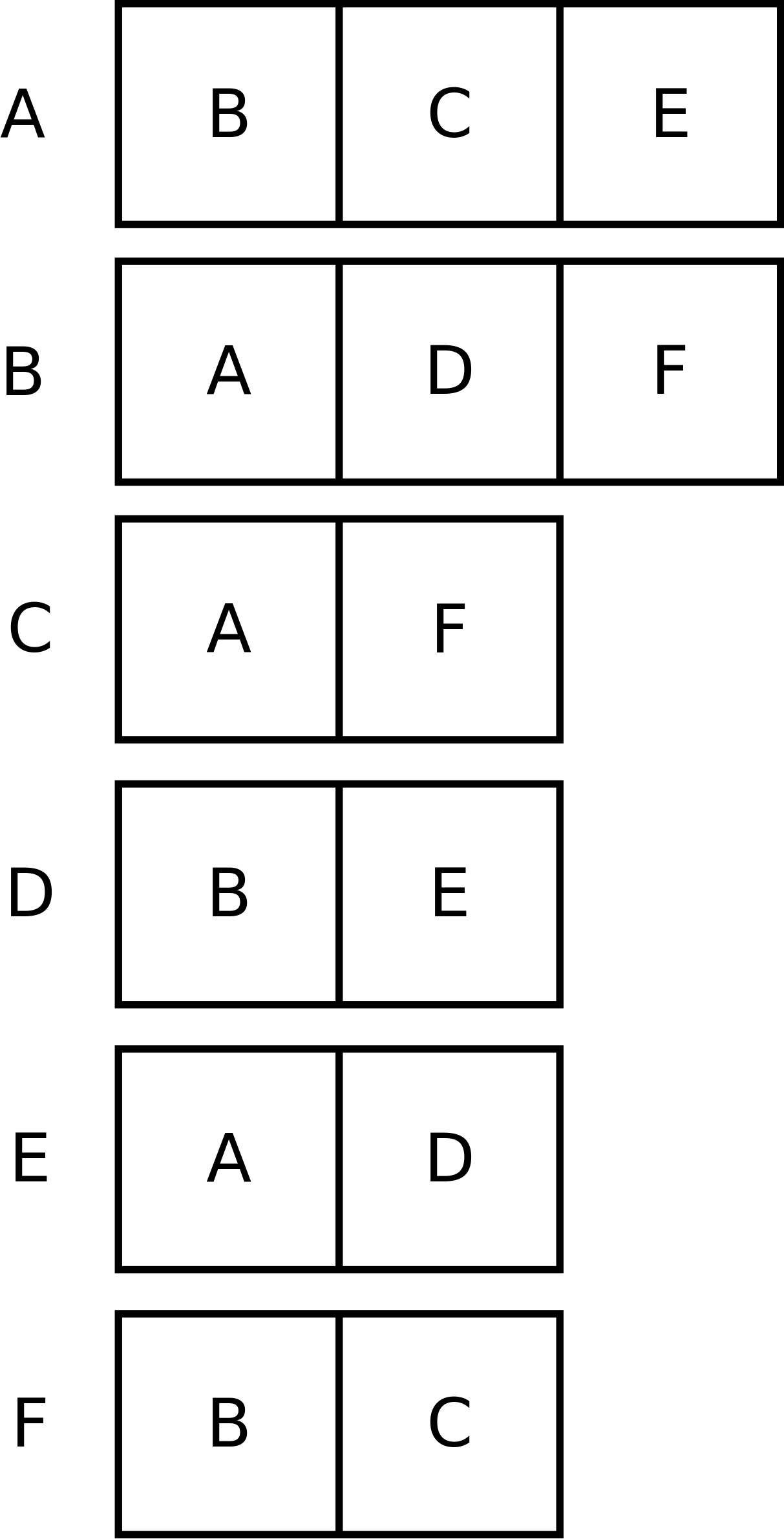
Sąsiadami wierzchołka A są B, C i E, sąsiadami B są A, D i F, i tak dalej. Ten sposób przechowywania grafu zwany jest listami sąsiedztwa. Zauważmy, że potrzebujemy tu tablic (lub innych struktur), które mają zmienną długość – gdybyśmy dla każdego wierzchołka przechowywali taką samą tablicę na potencjalnie wszystkie wierzchołki, sposób ten nie różniłby się niczym od macierzy.
W języku C++ najłatwiej użyć typu zmiennej zwanej wektorem. Bliższe informacje o używaniu wektorów można znaleźć na przykład tutaj. Z praktycznego punktu widzenia wektory różnią się od tablic głównie tym, że mają zmienną długość – można bezpiecznie dopisać element na koniec wektora, a jego rozmiar zwiększy się wtedy o 1. W tym wypadku potrzebujemy jednak wielu wektórów – jednego na każdy wierzchołek grafu. Można to osiągnąć deklarując tablicę wektorów:
vector<int> sasiedzi[6];
albo nawet wektor wektorów:
vector< vector<int> > sasiedzi;
Ile pamięci zużyje taka tablica list sąsiedztwa? Potrzeba tyle komórek pamięci, ile wynosi suma długości wszystkich list. Zauważmy, że każda krawędź pojawi się w dokładnie dwóch komórkach (na przykład krawędź A - B zarówno na liście sąsiadów A, jak i B), zatem łączna długość list to 2*liczba krawędzi w grafie. Dla porównania, macierz sąsiedztwa zawsze potrzebuje \(n^2\) komórek, gdzie \(n\) jest liczbą wierzchołków grafu. W przypadku skrajnym (jeśli każde dwa wierzchołki są połączone krawędzią) jest to tyle samo zużytej pamięci, jednak bardzo często listy sąsiedztwa dają dużą oszczędność pamięciową.
Zastanówmy się jeszcze, jak wypisać wszystkich sąsiadów ustalonego wierzchołka \(x\). Przy implementacji macierzowej z następującą deklaracją:
int graf[n][n];
odpowiednia pętla wygląda następująco:
for(int i = 0; i < n - 1; i++)
if ( graf[x][i] )
cout << i;
i zawsze wymaga przeglądnięcia wszystkich wierzchołków. W implementacji przez listy sąsiedztwa jest nieco trudniej, ale często szybciej:
for(int i = 0; i < sasiedzi[x].size(); i++)
cout << sasiedzi[x][i];
Nie należy jednak lekceważyć macierzy sąsiedztwa – jak już zauważyliśmy, jesli graf ma bardzo dużo krawędzi, to obie implementacje działają bardzo podobnie. W macierzy sąsiedztwa możemy też szybko (jedną operacją) sprawdzić, czy pewne dwa wierzchołki są połączone krawędzią. Na listach sąsiedztwa jest to znacznie trudniejsze.
Problem osiągalności i problem najkrótszej ścieżki
Skoro grafy przydają się przy tak wielu różnych okazjach, również algorytmy działające na grafach stanowią ogromnie bogatą dziedzinę algorytmiki. Na dzisiejszej lekcji ograniczymy się do algorytmów badających bardzo podstawowe własności grafów: osiągalność i odległość wierzchołków. Wróćmy jeszcze raz do przykładu sieci społecznościowej, i podajmy dwa różne przykłady grafów znajomości:
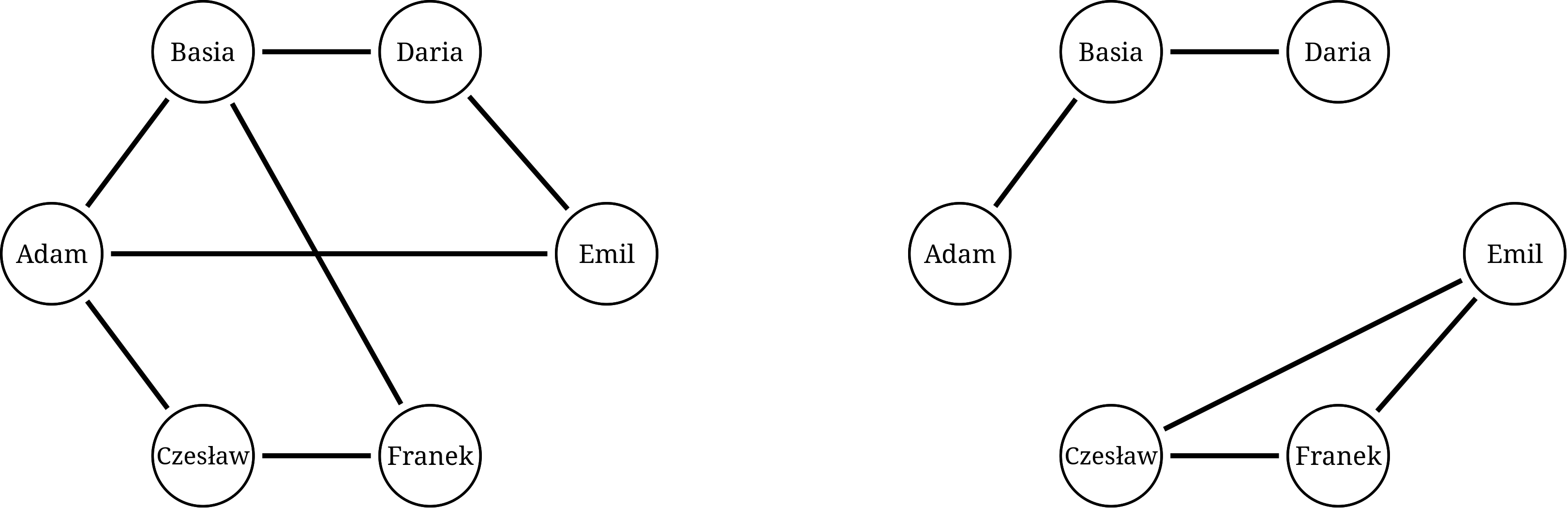
W pierwszym przykładzie od Adama do Franka istnieje ścieżka, czyli ciąg znajomości zaczynający się na A i kończący na E (np. Adam - Czesław - Franek, albo Adam - Emil - Daria - Basia - Franek). Mówimy, że wierzchołek F jest osiągalny z A (i odwrotnie). Graf, w każdy wierzchołek jest osiągalny z każdego innego, nazywamy spójnym. Drugi z podanych grafów nie ma tej własności – od A do F nie prowadzi żadna możliwa ścieżka. Zauważmy jednak, że zbiory wierzchołków {A, B, D} i {C, E, F} własność spójności mają, każdy z osobna – takie spójne części, na które graf się rozpada, nazywamy spójnymi składowymi.
Po tej dość dużej liczbie definicji wprowadźmy problem algorytmiczny, nawiązujący do legendy miejskiej z początku wykładu: mamy dany graf (na przykład sieć znajomości) oraz dwa z jego wierzchołków, oznaczmy je A i B. W prostym wariancie, zwanym problemem osiągalności, pytamy, czy między A i B istnieje ścieżka. Inaczej moglibyśmy to sformułować pytając, czy B jest osiągalny z A, albo też, czy A i B znajdują się w tej samej spójnej składowej grafu.
W wariancie nieco bardziej skomplikowanym pytamy, jaka jest długość najkrótszej ścieżki między A i B – przez ile krawędzi (znajomości) trzeba przejść, aby z A dotrzeć do B. To pytanie nazywa się problemem najkrótszej ścieżki. Okazuje się, że za pomocą jednego algorytmu można rozwiązać oba warianty zadania, a nawet odpowiedzieć na bardziej ogólne pytanie:
Mając dany graf i jego wyróżniony wierzchołek A (zwany źrodłem). jaka jest odległość od A do wszystkich pozostałych wierzchołków?
Przeszukiwanie wszerz
Załóżmy, że mamy zatem graf i źródło A. Odległość źródła od samego siebie równa jest oczywiście 0. Dla wszystkich sąsiadów źródła – wierzchołków z nim połączonych – odpowiedź musi być równa 1. Kiedy już oznaczymy wszystkich sąsiadów źródła, zauważmy, że z kolei dla ich sąsiadów odległość od źródła jest równa 2. Możemy bowiem dojść do nich w dwóch krokach, a z poprzedniego kroku wiemy, że nie możemy w jednym. Teraz z kolei wiemy sąsiedzi wierzchołków o odległości 2, których jeszcze nie rozpatrzyliśmy, muszą mieć odległość 3, i tak dalej. Można ten algorytm schematycznie opisać następująco:
odległość[źródło] = 0
dla k = 0, 1, 2, ...
dla każdego wierzchołka v takiego, że odległość[v] = k
dla każdej krawędzi (v,x)
jeśli x nie był wcześniej odwiedzony
odległość[x] = k+1
Po "Dygresji technicznej I" potrafimy poradzić sobie z instrukcją "dla każdej krawędzi (v,x)": zależnie od tego, jak trzymamy graf w pamięci, będzie to pętla przebiegająca wszystkie wierzchołki, lub elementy pewnej listy. Łatwo też sprawdzić, czy dany wierzchołek był wcześniej odwiedzony. Na przykład, wpisujemy na początku wszystkim wierzchołkom odległość równą -1, albo będącą bardzo dużą liczbą całkowitą. Wierzchołki, dla których ta wartość się nie zmieniła, to te dotychczas nieodwiedzone.
Jeszcze jeden wiersz algorytmu pozostaje zagadką – jak właściwie znaleźć wszystkie wierzchołki, które mają odległość k? Oczywiście można w każdej iteracji przeglądać wszystkie wierzchołki w poszukiwaniu odpowiednich, to jednak będzie wyjątkowo nieefektywny czasowo sposób. Spróbujmy podejść do tej kwestii z innej strony: zobaczmy, że kiedy przeglądamy wszystkie wierzchołki o odległości k, jednocześnie identyfikujemy i nadajemy odległość następnej grupie – tym, o odległości k+1. Przy rozpatrywaniu źródła pojawiają się sąsiedzi z odległością 1, potem właśnie ich rozpatrujemy, by znaleźć wierzchołki z odległością 2, następnie to je właśnie będziemy rozpatrywać...wystarczy zatem w momencie nadawania odległości zapamiętać wierzchołek, by za chwilę do nich wrócić. Wierzchołki będą więc rozpatrywane w kolejności takiej, jakiej zostały zapamiętane. Wygląda to trochę jakby wierzchołki ustawiły się w kolejce – do rozpatrzenia "podchodzi" pierwszy wierzchołek, z początku kolejki, a jego sąsiedzi, po nadaniu im odległości, ustawiają się na jej końcu.
Pomysł "kolejki" wierzchołków jest sformalizowany w algorytmice – kolejką nazywamy strukturę, do której możemy dopisywać dane, albo czytać z niej dane, przy czym elementy kolejki czytamy zawsze w takiej kolejności, w jakiej były dopisywane, od tych dodanych najwcześniej. O tym, jak to zrobić w C++, powiemy za chwilę, na razie nasz algorytm wygląda zatem następująco:
odległość[źródło] = 0
dopisz źródło na koniec kolejki
dopóki kolejka nie jest pusta
v = wierzchołek na początku kolejki
dla każdej krawędzi (v,x)
jeśli x nie był wcześniej odwiedzony
odległość[x] = odległość[v]+1
Algorytm ten nazywa się przeszukiwaniem grafu wszerz, a popularnie nazywany jest BFS, od angielskiej nazwy breadth-first search. Zastanówmy się przez chwilę, jaka jest jego złożoność. Każdy wierzchołek zostanie raz (i tylko raz!) włożony oraz ściągnięty z kolejki, a także dokładnie raz wpiszemy mu wartość odległości – na razie naliczyliśmy łącznie \(O(n)\) operacji, gdzie \(n\) jest liczbą wierzchołków. To, co pozostało do policzeni, to instrukcje "dla każdej krawędzi (v,x)". Zauważmy, że ponieważ każdy wierzchołek jest raz rozpatrywany, zatem raz przejdziemy przez jego listę sąsiadów. Jeśli więc używamy macierzy sąsiedztwa, to operacji będzie \(n^2\) (dla każdego z \(n\) wierzchołków, przeglądamy cały wiersz z \(n\) komórkami macierzy). Jeśli używamy list sąsiedztwa, operacji będzie tyle, ile wynosi łączna ich długość – czyli, jak ustaliliśmy, dwukrotna liczba krawędzi grafu. Całkowita złożoność w tym wypadku wynosi \(O(n + m)\), gdzie \(n\) jest liczbą wierzchołków, \(m\) – krawędzi grafu.
Zastanówmy się jeszcze, co się stanie, jeśli uruchomimy BFS w grafie, który nie jest spójny. Dość łatwo widać, że dla pewnego źródła x _ odwiedzi on tylko wierzchołki osiągalne z _x. Stąd już prosta droga do algorytmu sprawdzającego, ile jest w grafie spójnych składowych: uruchamiamy BFS z wierzchołkiem 0 jako źródłem, po czym patrzymy na wierzchołek 1. Jeśli nie został dotychczas odwiedzony, wykonujemy BFS od niego, jeśli był odwiedzony – pomijamy go. Potem to samo robimy z wierzchołkami numer 2, 3, ..., aż odwiedzimy wszystkie wierzchołki grafu.
Tak skonstruowany algorytm żadnego wierzchołka nie może odwiedzić dwukrotnie (gdyby doszedł do jakiegoś wierzchołka k przy dwóch uruchomieniach, na przykład startując z 0, a potem startując z 1, oznaczałoby to, że z 0 da się dojść do 1 – a więc z 1 nie zaczynałby już potem kolejnej iteracji). Łącznie zatem przeglądnie on cały graf w złożoności \(O(n+m)\) lub \(O(n^2)\) w zależności od tego, czy użyjemy list, czy macierzy sąsiedztwa.
Na zakończenie, dygresja o tym, jak w C++ napisać kolejkę:
Dygresja techniczna II: kolejka w C++
W bibliotece STL jest gotowa struktura, zwana po prostu kolejką (z angielska queue). Aby użyć kolejki (na przykład) liczb całkowitych wystarczy zadeklarować:
#include <queue> // to jest plik nagłówkowy, w którym znajdują się odpowiednie struktury
using namespace std; // alternatywnie, można pisać std::queue zamiast queue
queue<int> K; // deklaracja zmiennej K typu queue<int>, czyli "kolejki int-ów".
Aby teraz dołożyć element x na koniec kolejki, piszemy:
K.push(x)
Z kolei operacja:
K.front()
zwraca element stojący w kolejce na początku. Aby po obejrzeniu ten element usunąć z kolejki, wystarczy wykonać:
K.pop()
Oczywiście bardzo łatwo jest napisać własną kolejkę nie używając struktur z biblioteki STL, za pomocą tablicy z dwoma zmiennymi pamiętającymi pierwszy i ostatni aktualnie element kolejki. Pozostawimy to jako ćwiczenie dla dociekliwego Czytelnika.
Ankieta
Na zakończenie kursu gorąco zachęcamy Was do wypełnienia niezbyt długiej ankiety.